Mit Hilfe von Retrieval Augmented Generation (RAG) ein individuelles Assistenzsystem aufbauen
Gut ein Jahr ist es nun her, dass OpenAI mit ChatGPT an die Öffentlichkeit getreten ist und einen beispiellosen Hype um das Thema generative künstliche Intelligenz ins Rollen gebracht hat. So brauchte OpenAI lediglich 5 Tage, um die Marke von 1 Million Nutzer zu knacken und pulverisierte damit den bisherigen Rekord von Instagram aus dem Jahr 2010 mit 75 Tagen. Mit rund 1,85 Milliarden Besuchern im Mai ist ChatGPT im täglichen Gebrauch der Menschen angekommen.
Die Magie von ChatGPT
Die Gründe für diesen enormen Erfolg sind vielfältig: Sicher haben gezieltes Marketing und prominente Unterstützer wie Elon Musk ihren Anteil an der Popularität. Doch der Hauptgrund für das große Interesse liegt darin, dass ChatGPT generative künstliche Intelligenz einem großen Publikum zugänglich macht und keine Programmierkenntnisse voraussetzt. Schließlich findet die Interaktion in natürlicher Sprache statt. Die Ausgaben, die ChatGPT generieren kann, haben viele Menschen fasziniert und zum Staunen gebracht. Mit diesen Fähigkeiten hat ChatGPT großes Potenzial, den Menschen zeitintensive Routineaufgaben abzunehmen.
Wer ChatGPT schon einmal ausprobiert hat, musste allerdings feststellen, dass das System auch schnell an seine Grenzen kommt. Das ist insbesondere dann der Fall, wenn es um aktuelle Daten geht. Gleiches gilt auch für nicht öffentliche Daten, so wie es sie in jedem Unternehmen gibt. Ein solch großes Sprachmodell mit unternehmenseigenem Wissen als Unterstützung wäre dennoch weiterhin für viele Unternehmen sehr interessant und könnte viele Prozesse optimieren.
Retrieval Augmented Generation
Hinter den Large Language Models wie GPT-4, Llama oder Falcon stehen große künstliche neuronale Netzwerke. Ähnlich wie ein menschliches Gehirn können diese Sprachmodelle nur das wiedergeben, was sie gelernt bzw. trainiert haben. Hier besteht die Möglichkeit, eines der bekannten Sprachmodelle mit unternehmenseigenen Daten zu trainiert und anschließend den Nutzern zu Verfügung zu stellen. Doch analog zum menschlichen Gehirn kostet Lernen viel Zeit und Energie. Außerdem lernt der Mensch nicht alle Informationen auswendig, die ihm zugetragen werden, sondern er merkt sich, wo dieses Wissen gespeichert und gegebenenfalls nachgeschlagen werden kann. Diesen Ansatz verfolgt auch Retrieval Augmented Generation.
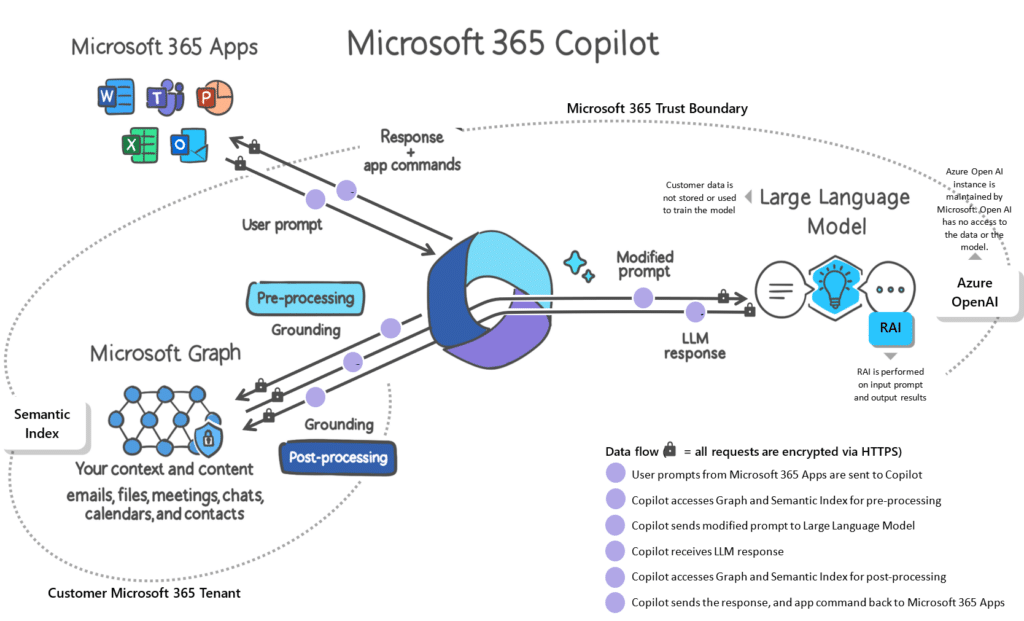
Der entscheidende Faktor bei dieser Herangehensweise ist das Zusammenspiel zwischen den beiden Komponenten, nämlich dem Information Retrieval und den generativen Sprachmodellen in natürlicher Sprache. Die erstere dient dazu, die gewünschten Informationen aus den eigenen Wissensdatenbanken zu extrahieren. Die Daten und Speicherorte können sich in Format und Art unterschieden wie Intranet, Blob Storage, Sharepoint, PDFs, Emails, Word-Dateien oder PowerPoint. In einer Microsoft Infrastruktur bietet sich die Azure Cognitive Search gut an. Diese kann entweder Keyword-basiert oder mithilfe von Embeddings eine vektorbasierte Semantikanalyse im unternehmenseigenen Datenbestand durchführen und die relevanten Informationen extrahieren. Diese Informationen werden dann in Textform respektive natürlicher Sprache als Eingabe des generativen Sprachmodells genutzt.
Genauere Ausgaben dank Prompting
Die Implementierung basiert auf einem sogenannten Prompt Flow. Dieser bildet ein Gerüst um den Information Retrieval und generativen Prozess; außerdem dient dieser als Interface zum Anwender. In diesem Flow werden die Anfrage des Nutzers sowie der Chatverlauf als Eingabe verwendet. Anschließend wird diese in verschiedenen Teilprozessen analysiert und um spezifische Prompts bei der Eingabe in die Sprachmodelle ergänzt. Als Prompt wird die Eingabe an ein LLM bezeichnet. Durch gezieltes Prompting können bessere und spezifischere Ausgaben generiert werden. Dieses Verfahren nutzt auch der Microsoft 365 Copilot.
Die Vorteile von Retrieval Augmented Generation liegen nicht nur darin, einen Sprachassistenten mit Wissen zu unternehmenseigenen Daten erstellen zu können, sondern es ist auch kein aufwendiges Training von eigenen LLMs notwendig. Dadurch können Anpassungen im Datenbestand schnell und flexibel in das Modell integriert werden. Zudem können durch die spezifischen Prompts nicht nur genauere Antworten generiert, sondern auch Referenzen für die zugrunde liegenden Daten ausgegeben werden. Daher ist es nicht überraschend, dass immer häufiger Sprachassistenten in bekannte Anwendungen integriert werden.